
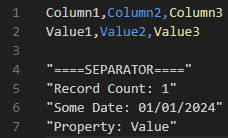
CSV format is pretty common and sometimes has a footer for many reasons. A common reason can be that systems producing those CSV files want to put auditing properties for cross-checking or simply a default format due to their design. In my case, the CSV looks like the below screenshot. The footer is separated by an empty line following a separator then some properties.
To get rid of the footer, there are many ways that don’t even modify the file. For example, I used to declare an External Table for a CSV having a footer and remove the footer by creating a view with a filter condition something like below.
WHERE TRY_CONVERT(<Actual Type>, <First Column in the CSV>) IS NOT NULL.It just doesn’t work in the case when the first column’s data type is textual, e.g., CHAR or VARCHAR. This solution was also annoying when I had to use TRY_CONVERT/TRY_CAST on non-text columns to get their original format in the view. It also shifted my schema validation process on raw files to the view level.
Once a Spark runtime is available for my team, a lot of potential solutions are unlocked. One among them is to use fsspec, a filesystem interface in Python, to remove the footer with its tail function.
FSSPEC
fsspec is the backend of some utilities in Microsoft Spark Runtime. If you import fsspec in a notebook, you will find the implementation classes are AzureBlobFileSystem and OnelakeFileSystem for Azure Synapse Analytics and Fabric respectively. Those classes are internal and available in Microsoft Spark Runtime for their services.
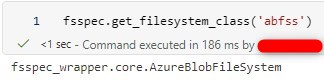
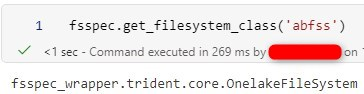
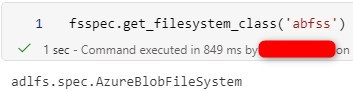
A quick note if we import pandas, a popular data analysis/processing library, before importing fsspec, the actual implementation will be adlfs instead of an internal one. More information can be found in the link below. In short, the adlfs implementation does not work with Managed Identity in Synapse or the default connection in Fabric.
https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/synapse-file-mount-api
Furthermore, mssparkutils.fs only has the head function for showing top n-bytes (row if you parse), but not the tail, which is declared in fsspec. This means mssparkutils.fs is not the solution I am looking for. It seems I will have to use fsspec directly.
https://filesystem-spec.readthedocs.io/en/latest/api.html#fsspec.spec.AbstractFileSystem.tail
Solution
The idea is simple and straightforward. I read the first 1024 bytes from the end of a CSV file and find the last empty line if applicable. Once the index of the empty line is located, I will write the file from the start to that index to a new file. The final result is a CSV file without a footer and can have its schema validated easily.
Step 1 – Read the tail
# file_path to the CSV file in Azure Blob Storage/ One Lake
# In this case, I only read 1kb from the tail. If you know your footer is longer, use a bigger number.
tail : bytes = fs.tail(file_path, size=1024)
total = fs.size(file_path) # We get total size in bytes of the fileStep 2 – Find the empty line/separator
# import re priorly
match_it = re.finditer(b'(\r?\n){2}', tail, re.MULTILINE)
# Since I want to detect empty line and can be a heap of them, I store all matches in a # queue. In other words, empty line is the separator.
q = deque(match_it, maxlen=1)
# Try to find out if the file has footer or not
separator_idx = -1 if len(q) == 0 else q.pop().start() Step 3 – Extract properties in the footer (Optional)
if separator_idx > -1:
record_count_m = re.findall(b'Record Count: (\d+)', tail)
some_date_m = re.findall(b'Some Date: (\d{2}\/\d{2}\/\d{4})', tail)
record_count = int(record_count_m[0])
some_date = some_date_m[0].decode()Step 4 – Store the CSV body in a new file
# CSV body's cutoff index = total size - tail's read size + separator index
csv_cutoff = (total - 1024) + (separator_idx if separator_idx > -1 else 1024)
csv_body = fs.read_block(file_path, 0, cutoff)
# Store the CSV body in a new file somewhere
fs.write_bytes(new_file_path, csv_body)Summary
Sometimes being curious is helpful like this case when I check the abstract functions of fsspec. I really hope Microsoft will put the tail function to mssparkutils.fs in the future as it is handy in some cases like checking the last entries of a log file or the footer of a CSV file like in this scenario. Hope you find this article helpful.