TL;DR
DBT Fabric supports unit test feature but doesn’t support models having Common Table Expression (CTEs). I have setup a test case and found the issue. My solution is to use 2 regular expressions to fix the issue. The first regular expression is used to detect if a model has CTEs, while the second one is to extract the final selection statement and put CTE definition part on top of any generated SQL code in 2 internal macros relating to the unit test feature.
You can find my code in this zipfile on Github at this link
https://github.com/user-attachments/files/16408951/macros.zip
The issue is raised in DBT Fabric Adapter repository on GitHub at this link
https://github.com/microsoft/dbt-fabric/issues/185
The details of my finding is presented in below sections.
DBT Unit Test
DBT has had test feature for a long time and now be classified as data test in version 1.8 and onwards. This is sensible since the data test aims to test quality and uniqueness of columns in a model or the statistics of the whole model. Unit Test is adopted for these reasons:
- Allow to test complex transformative logics in a data model with multiple scenarios without actually deploying it to the warehouse.
- A fail in data test could be the result of a bug of an internal CTE or transformative logic.
With the great benefit, I was super eager to hands on the feature with a test scenario like below.
Note: you are now familiar with unit test, I suggest have a look at PyTest at this link https://docs.pytest.org/en/stable/. You will find some terms will be used by DBT’s unit test feature
Scenario
Test Model
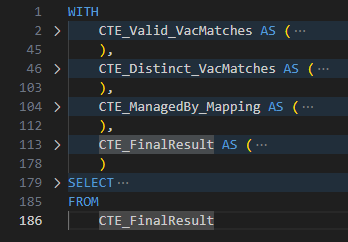
I developed a conform model about Vacancy Referrals with 4 CTEs to find out which staff referred which vacancy to which customer at what time. You can see from the screenshot that the SQL code is pretty long and has some complex logics in the collapsed sections.
Fixtures
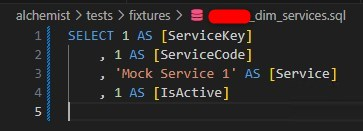
Fixtures are self-prepared resources for unit tests. They can be configurations, environment variables, or mock data. In DBT unit test, they are mock data. DBT supports inline mock data, or in a CSV file and a SQL file. However, if you wish to test your model, which still not exist and has non-exist related models/views/seeds in the warehouse, you would have to choose SQL.
According to DBT doc site, all fixtures must be put into fixtures folder in tests folder, which is configurable if you don’t want to stick with that standard name.
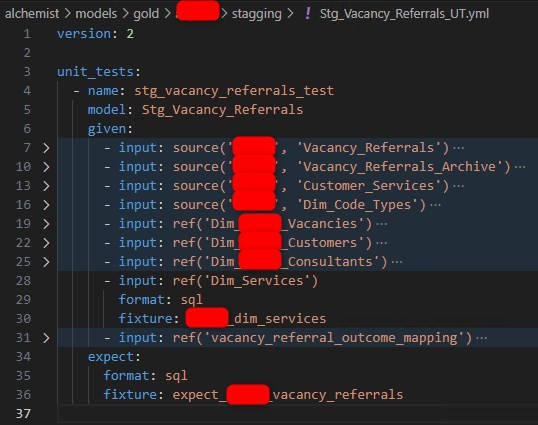
I created a YML file declaring all unit tests applying to the model as above. All relation macros like source and ref used in the model needs to be overridden with mock data. Even the expectation, which are expected rows, is also declared in a SQL file.
My tip is to prepare mock data in CSV files in a user friendly editor, e.g., Excel, then convert to SQL selection statements by an online tool, which is a heap on the internet.
Execution
Now run this command to execute the test.
dbt test -s Stg_Vacancy_Referrals test_type:unitIssue
DBT log states that there is an error around the WITH statement, but I am pretty sure there’s nothing wrong with it. After checking the log for a while and looking around for the implementation of the unit test feature in DBT Fabric, I found this.
Path: .venv/Lib/site-packages/dbt/include/fabric/macros/materializations/tests/helpers.sql
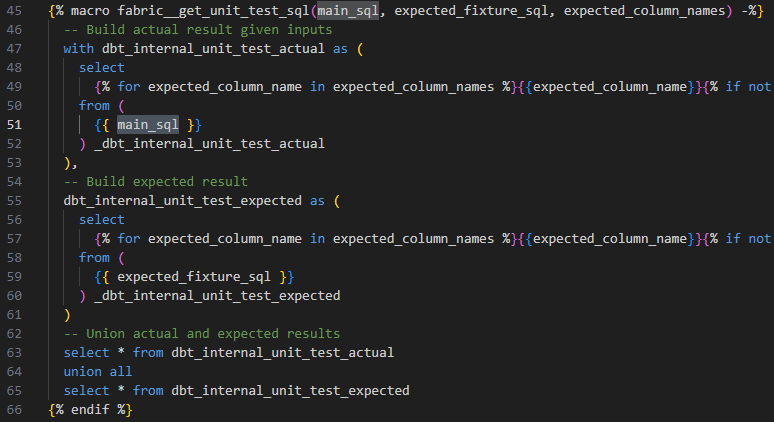
The Fabric adapter put the main_sql, which is the actual code of my model, inside a subquery. Since my model uses CTEs, the generated SQL code won’t work.
Solution
My idea is to use a regular expression to extract the final selection in my model and put all CTEs on top of that macro’s SQL query. Fortunately, the idea becomes feasible because DBT supports some Python modules including re, which is for regular expression, in their Jinja template engine. Technically, I can compose an expression and test it in Python before putting into those DBT’s Jinja macros.
Disclaimer: I am not a Regex Expert, so please do not expect my expressions would work with every coding style. You can enforce the style by a SQL lint to minimize the effort of maintaining your expressions.
My regular expression is something like below. Firstly, I use the regex to check if the main_query has any CTEs. If it doesn’t have one, just stick with the default code.
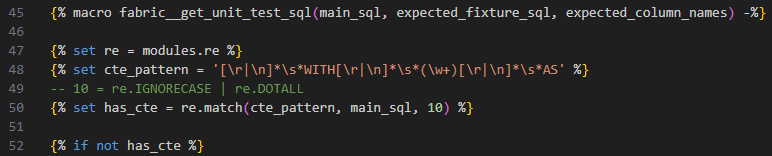
When the main_query has CTEs, another regex is used to extract the final selection statement. The final selection is removed from the main_query that is now the CTE definition part. Next, put the CTE definition part on top then the internal unit test CTEs. The implementation as below.
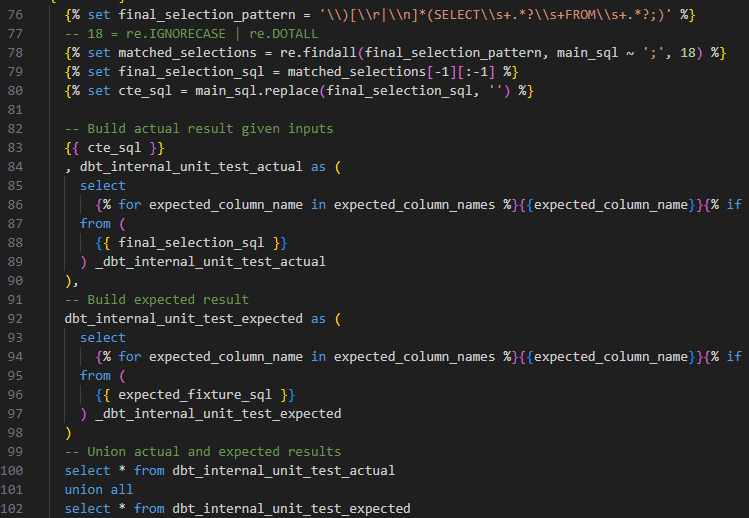
I thought it was over and could be able to run the unit test gain without any issues. I was wrong. Another part in this process got the similar issue too. It is the get column name macro, which is used to find out column name of any SQL query.
Path: .venv/Lib/site-packages/dbt/include/fabric/macros/adapters/columns.sql
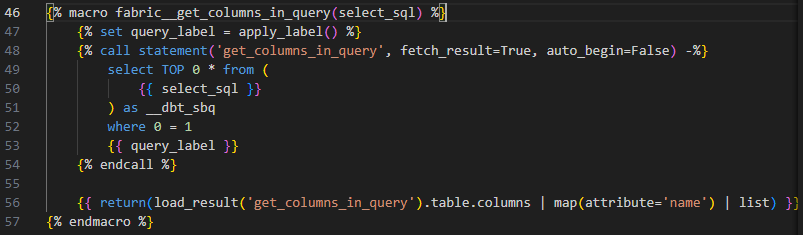
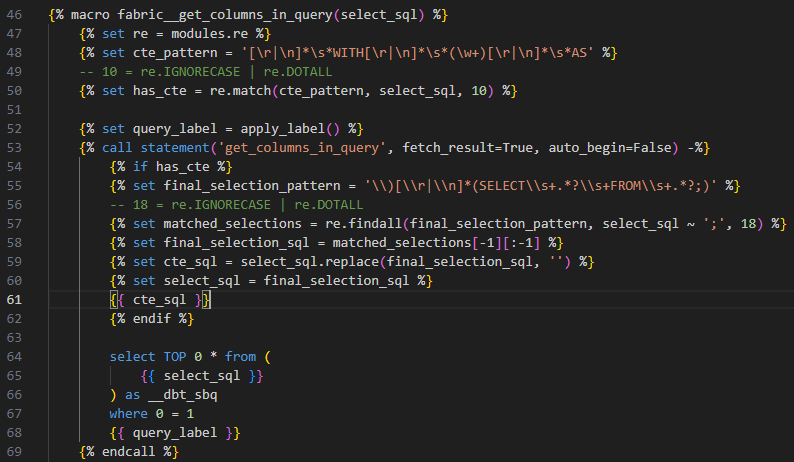
I can see the same issue lying in here. The fix is the same as applied to the unit test code generator.
Result
After applying those fixes, the unit test now can run with my model. The result is as below.
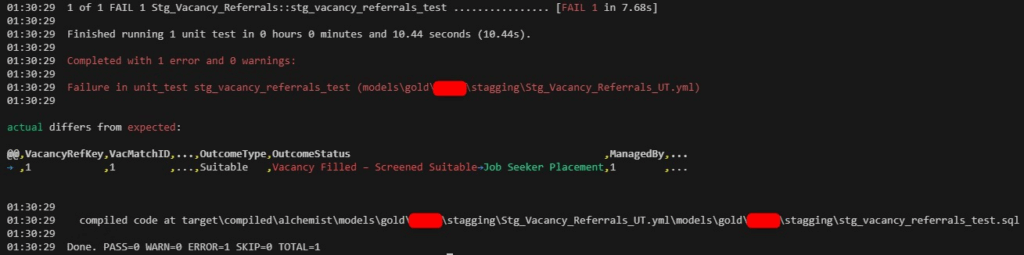
My model was not deployed, but SQL codes were actually executed in Fabric Warehouse.
Summary
I find the unit test feature super helpful. During doing the physical data modeling, I can quickly test some models without creating/deploying all related models but just use mock data. This become handy when the DBT project gradually grows in time with models convoluted to models, and this can save a lot of time to measure the impact of a change in a super complex model to its downstream.
Hope you find this article helpful and informative.