
DBT is very handy when comes with a data documentation site generation packing data model lineages. It, however, is disconnected from exposures, which can be any application using models documented in DBT. To add exposures into DBT requires a little efforts by either manually write yml files or generate them automatically depending on how the data-consuming app or BI tool can support.
At Workskil, we use PowerBI as the main BI tool beside very few Excel reports. The very first approach of our team was to use the default format, PBIX, and deploy semantic datasets and reports separately. We do have deployment pipelines and can see historical deployments, but a question echoed in my mind was how can our team can track changes happening in both datasets and reports. Git Integration option in Workspace Settings was the only option, but requires some basic Git and a bit knowledge of developing SSRS reports as well as a Premium Licence.
PowerBI Project (preview feature) is the game changer that helps me not only to bridge the gap between PowerBI side and DBT but also provides a simpler solution to version control PowerBI datasets and reports. Furthermore, Business Intelligence Analysts only need to learn basic Git commands or just use Visual Studio Code or any Git GUI-tool to submit changes. Since a PowerBI Project for a semantic model stores information around data connections and queries, it sparks a new idea in me that will extract table names from its model file and craft exposure yml files for DBT. Yet to mention that using PowerBI Project save us a Premium Licence if we want to depart from using Premium Capacity.
graph LR
bi_desktop[PowerBI Desktop]
subgraph git_bi[PowerBI Repo]
file[.PBIP]@{shape: doc}
end
subgraph artifact[Artifact]
exposure[DBT exposure YML]
doc[DBT Doc Site]
end
subgraph devops[Azure DevOps]
bi_devops[PowerBI Pipeline]
dbt_devops[DBT Pipeline]
end
bi_desktop [email protected]>|1.push| file
git_bi [email protected]>|2.trigger| bi_devops
bi_devops l3@-->|3.generate| exposure
dbt_devops -.->|use| exposure
dbt_devops l4@-->|4.generate| doc
l1@{animate: true}
l2@{animate: true}
l3@{animate: true}
l4@{animate: true}
linkStyle 0,1,2,4 stroke: blue;Save A Dataset As A PowerBI Project
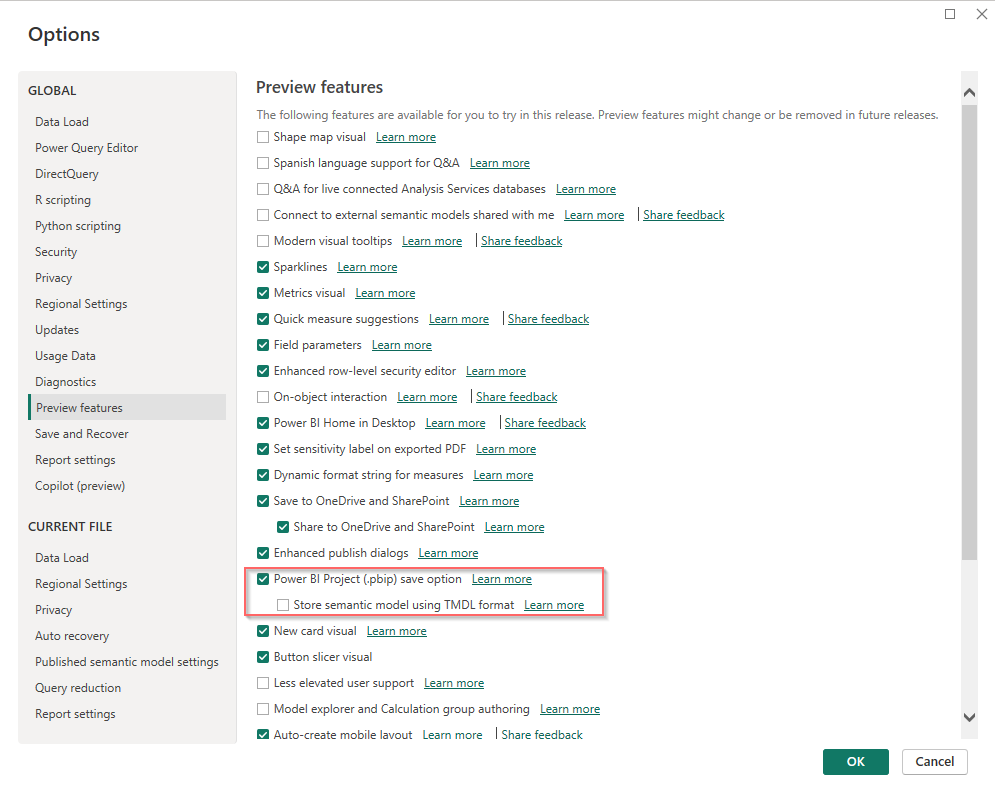
To turn on the PowerBI Project save option in PowerBI Desktop, it can be found in Options/Preview Features. Note that, please don’t turn on Store semantic model using TMDL format due to these reasons:
- TMDL is a new format and the only parser I could found is in a C# feature package, which is subject to change. I will need to wait for an official parser in Python, unless I am willing to implement it by myself, which costs a lot of time.
- In contrast, the default format for every file in a PowerBI Project is JSON, which is common and has heap of parsers in every programming language.
Once saved a semantic model as a PowerBI Project, the below screenshot demonstrates how the folder structure looks like. The pbip file is the main entry to open the dataset in PowerBI Desktop. The .Report folder is where configurations of all pages, visuals, and everything that you see in PowerBI Desktop will be stored in there, while all tables, references, and transformation steps in PowerQuery are stored in the .SemanticModel folder.

Parse model.bim File
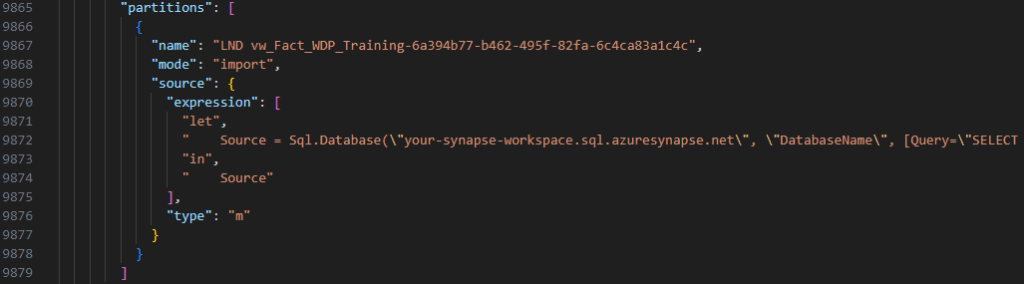
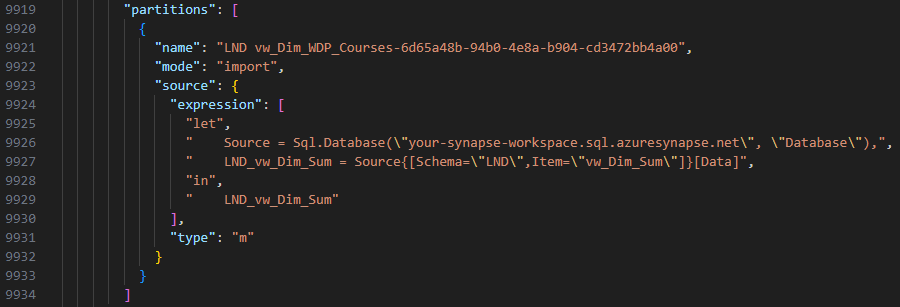
Sql.Database is the main Power Query M function to connect and extract data from a target database. It uses 3 parameters if we want to use a SQL query. Otherwise, it uses 2 parameters to create a connection firstly before selecting a view/table in the second step. Remember these patterns as I will need them later in my model.bim parsing file. My approach is to build a Python script with a bunch of Regular Expressions that will extract used parameters in a SQL.Database function then use a SQL parser for parsing the SQL query in Query section.
There are many SQL parser packages can do the job with SQL queries in model.bim. Nevertheless, some of my queries use OPENROWSET leading to syntax errors when I used those parser packages. I finally found sql-metadata because of asking CoPilot in Bing, which surprised me as the package is exactly what I need in my situation. The package is handy and saved me a lot of time as it doesn’t validate syntax in a SQL query but aims to extract table names only.
CI/CD Pipeline & Publish Exposure YML Files
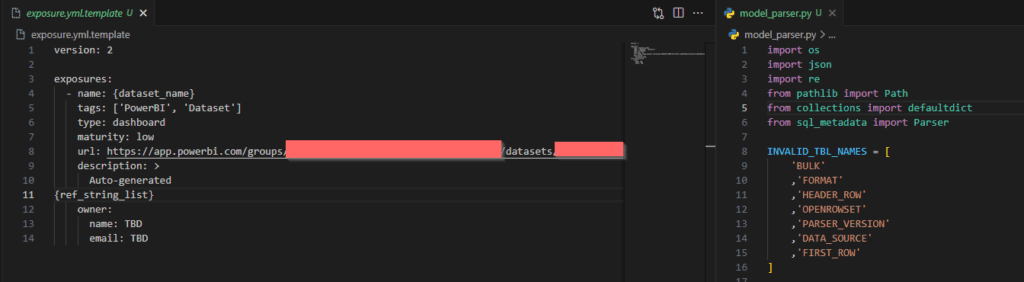
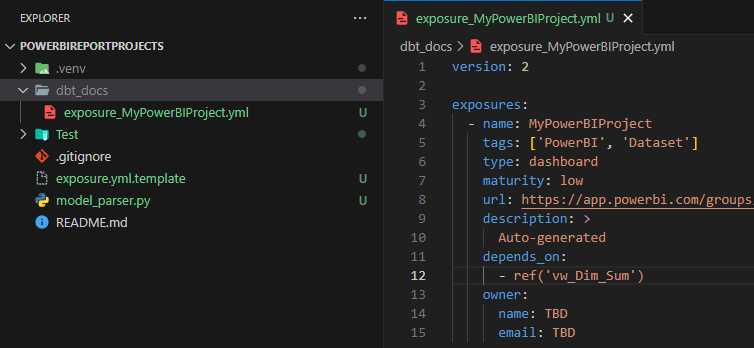
After extracting of table/view names in all semantic models, prepare an exposure yml file having Python string format variables like the below screenshot. It should have at least 2 placeholders for the dataset name and list of used table/view names wrapped in ref function as I assume none on my team members doesn’t connect to a raw (source in DBT) file. In a newer version of my parser, the template file has the url parameterised as I use PowerBI Restful API to extract a dataset url in PowerBI Service.
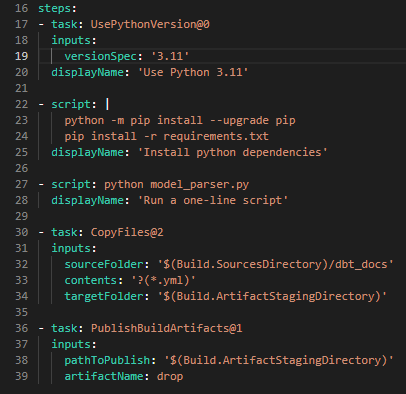
We have 2 separate repositories for the DBT project and PowerBI Projects, so we would want to have all generated YML files packaged as an artifact in DevOps. This artifact will be promoted to @Release and used in the DBT project’s pipeline generating the documentation site.
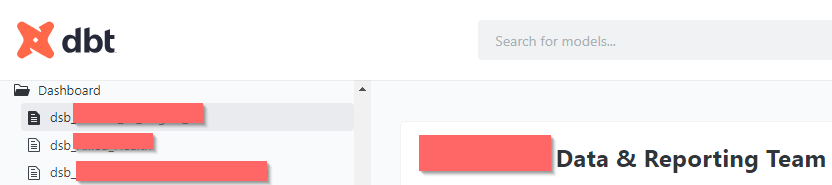
Conclusion
We have 2 separate repositories for the DBT project and PowerBI Projects, so we would want to have all generated YML files packaged as an artifact in DevOps. This artifact will be promoted to @Release and used in the DBT project’s pipeline generating the documentation site.
Leave a Reply